0x00 前言
在上一篇文章中我们了解了内存中数据的存储方式,其中,链式存储结构十分适合存储常常修改但不常访问的数据。事实上,我们生活中常常遇到的就是这种数据。
实现链式存储的方式有很多,几乎所有的编程语言都能够做到,对于现代的面向对象编程语言,编写某种数据结构要简单得多。但是考虑到很多高校仍在使用面向过程的C语言来进行数据结构课程的教学和考核,本文也使用C语言来编写示例代码。
0x01 链表
什么是链表?
还记得上一篇文章中提到的地铁线路数据吗?对于一条地铁线路而言,它由许多站点名称按照一定顺序串连组成,从地铁线路图上来看,这样的一条线路就像是长长的一条线,我们称这种结构为线性表。为了方便理解,这里需要说明,线性表的英文是Linear List,其实应该翻译成线性列表更准确,表示数据是以一种线性结构一个接一个排列的,不存在分叉或者平行的情况。
线性表是一种逻辑结构,我们在内存中存储线性表的时候不一定真的要把数据一个接一个按照顺序结构存储,也就是说,一组特定逻辑结构的数据在计算机中存储时可以有顺序和链式两种存储结构。我们称以顺序结构存储的线性表为顺序表,称以链式结构存储的顺序表为链表。
这么看来,链表其实就是一种线性表,那么我们常说的单链表、双向链表又是什么东西呢?
让我们回忆一下上一篇文章中提到的链式存储结构,为了在散乱分布的数据中理出顺序,我们在每一个数据旁边都存储了它的下一个数据的内存地址,这样一来,我们就能从第一个数据开始,沿着一个方向按顺序找到所有的数据。可是这种结构有一个小问题,如果想知道某个数据的上一个数据的位置,就成了天大的难题。由于这种方式构造的链表只能往一个方向寻找数据,所以也被称做单链表,也称作单向链表。
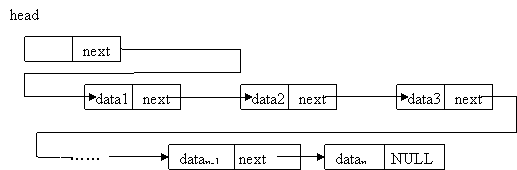
双向链表
其实通过略微修改链表的存储方式就可以实现上面提到的快速查找当前数据的上一个数据的需求。只要在存储数据时,不仅保存下一个数据的内存地址,也同时保存上一个数据的内存地址,就可以像查找下一个数据一样简单地访问上一个数据了。这种结构被称为双向链表。

除此之外,为了满足不同数据存储的需求,人们还定义了循环链表、块状链表、十字链表等衍生结构,这些特殊的列表在以后的文章中会有所涉及。
0x02 Talk is cheap
熟悉了链表的结构,接下来让我们尝试使用C语言构造一个最简单的单链表吧。
实现单链表的方式有很多很多,我个人比较倾向于让链表的使用尽可能简单的写法。我们先思考一下一个单链表需要包含哪些内容——首先,我们需要存储节点的数据,在每一个节点数据旁边,我们还需要存储下一个数据的内存地址(也就是C语言中的指针)。为了简单,我们将节点数据和内存地址包含到一个叫做ListNode的结构体内。
1 | typedef /*some type*/ listElement; |
第一行的类型定义是为了将来可以让链表节点包含不同的数据类型,将需要构造链表的数据类型定义为listElement,之后修改类型时就不需要修改ListNode结构体而只需要修改typedef了。
在上面的结构体定义中,我们定义了链表节点ListNode结构,包含一个类型为用户定义的listElement类型的数据和一个ListNode指针类型的指针,用来存储下一个节点的地址。
在C语言里,创建一个结构体变量其实挺麻烦的,我们需要写struct ListNode node才可以创建一个叫做node的结构体变量。为了使得代码没有那么复杂,我们有两件工作可以做:
因为
struct ListNode共同表示一个链表节点类型,我们可以做类型定义如下:1
2typedef struct ListNode node;
typedef struct ListNode* pnode;这两行代码的意思是,将
struct ListNode定义为node类型,而将struct ListNode的指针定义为pnode类型(p代表pointer)。这样一来,在创建链表节点的时候就不需要多写一个struct关键字了。第二件事是为链表节点编写构造函数。由于C并不是面向对象的编程语言,自然不存在类的概念,也没有构造函数这一说,这为我们做结构体初始化带来了不便。就拿链表节点举例,如果我们希望新建的链表节点的
next默认为空指针NULL,就必须每创建一个链表节点都手动将它的next变量赋值为NULL,这显然有些不方便。我们可以模仿C++的类构造函数,自己写一个结构体的构造函数,为了简便,我们默认已经按照第一条所说的方法做了类型定义。1
2
3
4
5
6
7
8
9
10
11
12
13
14pnode nullListNode() {
//创建一个空节点,返回其指针
pnode tmp = malloc(sizeof(node));
tmp->next = NULL;
return
}
pnode newListNode(listElement data, pnode next) {
//用传入的数据创建一个节点,并返回其指针
pnode tmp = malloc(sizeof(node));
tmp->data = data;
tmp->next = next;
return
}这样一来,我们就可以调用
nullListNode()和newListNode(data, next)两个函数快速创建需要的节点变量并得到他们的指针了。
接下来,我们需要链表可以添加节点,其实我们可以在每个要添加节点的地方都手动创建节点、修改前一个节点的next变量、修改所创建的节点的next变量,但是这样写起来不是很方便,还很容易出错,为了方便起见,我们编写一个插入节点的函数:
1 | int insertToList(pnode head, int index, listElement data); |
表示在以head节点开头的链表的第index个节点后插入内容为data的新节点。
同时,我们可以继续构造一些常用的函数:
1 | //删除head节点开头的链表的第index个节点 |
在给出详细代码之前,我们需要最后思考一个问题——我们明明是要写一个单链表,为什么却只创建了链表节点这一个结构,按理说不适应该有一个单链表的结构体才符合逻辑吗?
答案是:因为单链表本身太太太简单了,我们只需要知道链表的头节点指针就完全掌握了这个单链表所有的信息,所以就算我们创建一个List结构体,里面也基本只有一个头节点变量,一个单链表在代码中有了List结构体也是一个变量,没有它也是一个变量(头节点),创建List结构体的意义就不那么大了。但是这并不代表对于任意数据结构我们都没有必要为这个数据结构本身创建结构体,就拿也很简单的双向链表为例,对于一个双向链表,我们往往都要保存头节点和尾节点这两个变量的指针,这样,如果没有一个双向链表结构体,对于每一个双向链表,我们就需要单独保存两个变量。对于一些更复杂的数据结构,我们甚至可能需要保存更多变量,这样就显得很不方便。但如果我们为每个数据结构单独创建一个结构体,那么我们只需要维护这个结构体变量就可以了,代码会大大简化。因此,为了保持同步,我们也为单链表创建一个结构体List(虽然不一定非要这么做):
1 | typedef struct List list; |
这样一来,我们就可以简单维护一个List结构体变量来维护整个链表了,为了简便,我们把刚才定义的和链表有关的函数中的参数pnode head全部改为plist lst并且给出完整代码:
1 | //删除head节点开头的链表的第index个节点 |
这样,我们就创建了完整的单向链表的代码,使用时,只需要通过list myList;或list myList = newList(head);这样的代码创建链表,调用写好的链表操作函数进行需要的操作就可以了,比如下面这段代码就表示以firstList链表中第一个值为123的节点为头节点,把这个节点以及它之后的所有节点作为secondList这个新链表:1
2pnode target = findInList(&firstList, 123);
list secondList = newList(target);
0x03 下集预告
在本篇文章中,我们学习了链表的定义并使用C语言编写了一个创建、维护单链表所需的代码(这些代码我还没来得及编译运行,不一定没有Bug)。希望文中的写法可以比教材上的写法更加容易理解,事实上,上述函数并不一定全都要实现,只要根据自己的需求实现相应的功能就好了。
编写这些代码时,我的宗旨是“能用一行代码、一个函数完成的内容绝不要写成好多行,更不要让相同的代码片段重复出现”,如果你觉得这种思路有助于让你的代码更清晰,那就试着在写自己的代码的时候也应用这个宗旨吧,事实上,它还可以让你的代码调试更加轻松。
在下一篇文章中,我们会学习一个稍微复杂一些的的数据结构——树,并且来看看上篇文章中提到的查找和修改都比较快的神奇结构是什么。